OpenStack deployed across multiple sites is the ideal path for enabling distributed workloads and building sovereign, resilient cloud platforms. In reality, however, most installations remain single‑region and operationally isolated — not from lack of ambition, but because architecture options on the table are often messy, hard to maintain, and demand significant engineering effort and ongoing cost. That outcome is understandable: community projects rarely deliver turnkey solutions for every complex scenario out of the box. This blog will trace the history and current state of OpenStack multi‑region deployments, outline several effective techniques, and describe recent Uniview engineering that, as possibly most viable option, helps CSPs achieve multi‑sites multi-regions infrastructure at minimal cost.
History Initiatives
The history itself makes this clear. Over the years, the community explored many different multi‑region initiatives, and each one ended up totatly different results but provided intriguing perspectives. Early efforts such as the Cascading Solution, Tricircle, and Trio2o attempted to unify regions under a single logical control plane. But most of these initiatives never produced deployable, production‑ready code. They demonstrated the ambition of the ecosystem, but also exposed how difficult it is to stretch OpenStack’s architecture beyond its original design boundaries.
By Keystone Spanning Regions
More recent deployments shifted toward pragmatic models. In the Isolated Regions (Federated) approach, each region operates as an independent cloud but trusts others through Keystone federation — improving failure isolation but offering no unified control plane. Stretched Control Plane architectures attempted to run a single OpenStack cluster across multiple datacenters, but required extremely low‑latency links and synchronous database replication, making them viable only within certain distance. Hub‑and‑Spoke models centralized identity and management services in a “hub” region while “spoke” regions provided local compute and storage, but this introduced tight coupling and single‑point‑of‑failure concerns. These models work, but each comes with architectural tradeoffs that limit true multi‑region autonomy and scalability. Often the it shows as below.

In real deployments, each OpenStack region tends to become its own snowflake: APIs drift, upgrade paths diverge, identity synchronization breaks, and cross‑region networking ends up as a fragile patchwork of tunnels and manual stitching. The risk of cascading failure looms whenever a shared service or component goes down. When disaster recovery is considered, cross‑site state synchronization and data replication on other hands, are barely facilitated by those options, and such inconsistency leads to high cost implementatioin. That gap between the promise of multi‑region, multi‑cluster clouds and the practical difficulty of maintaining them deters many stakeholders. This is where Uniview changes the equation.
By API Orchestration With Nothing Shared
Instead of forcing operators to stretch OpenStack beyond its safe boundaries, Uniview introduces a clean, externalized control layer that treats each region as an autonomous, healthy unit — then integrates them through a consistent, cloud‑agnostic orchestration plane. Identity, workload placement, replication strategy, and failover logic are unified without modifying or hacking the underlying OpenStack services.
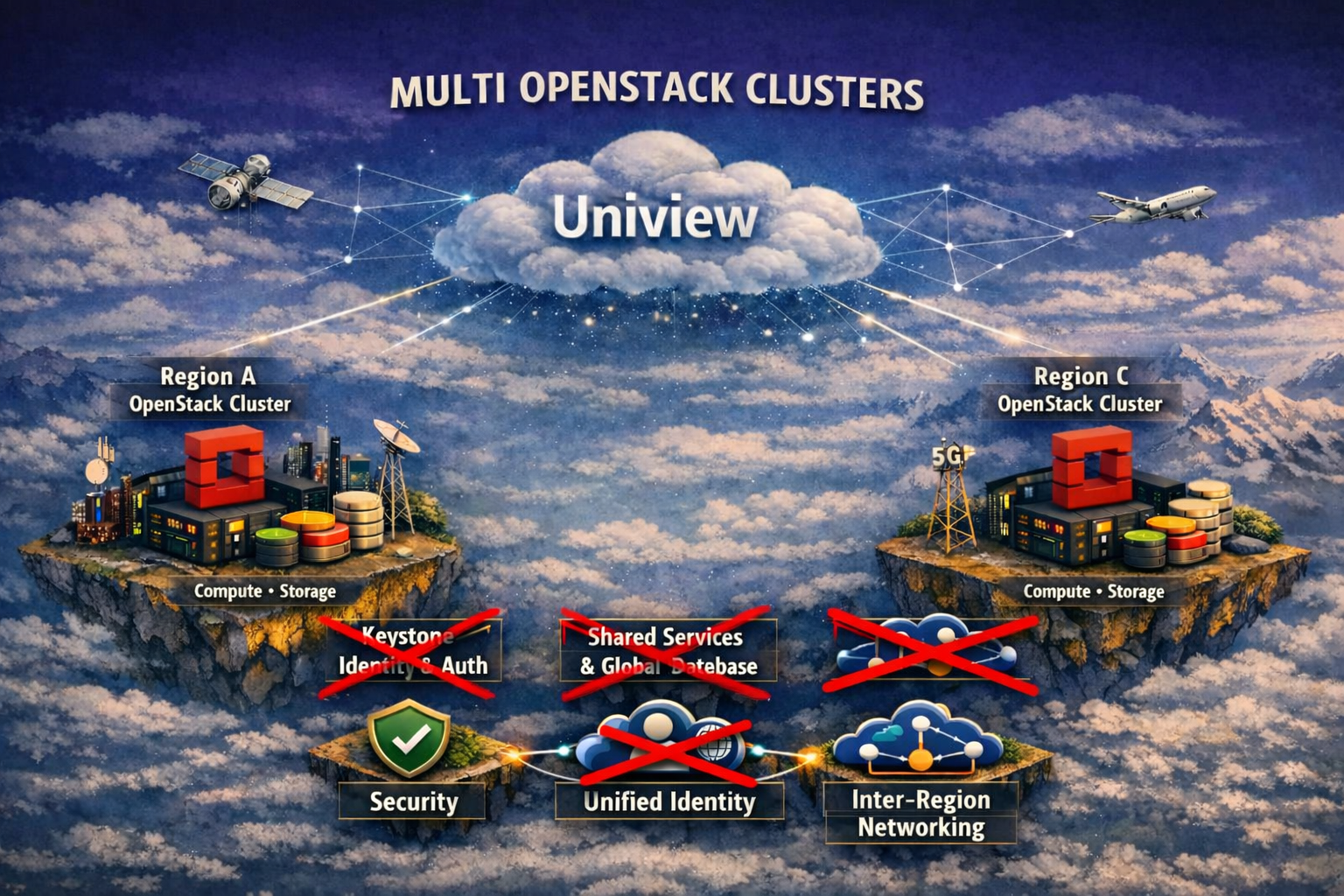
From architecture above, new layout doesn't require Keystone to span regions or sites, and each install is fully autonomous with its own part. They even don't need be at the same version. Shared database between regions and sites, and the latency handling are not needed either. Due to orchestration is fully at API level, there is no requirement on existing Keystone, database to support OIDC, or SAML module, no keystone role/policy change, no user SSO mapping, each keystone can just join as is.
The result is a truly modern multi‑sites architecture:
Each site/region remains autonomous for stability
With no shared control‑plane or common services between clusters, failure domains remain local — a cascading fault in one region does not automatically impact other, isolated clusters.
No disruption for integrating running Production cluster
With this layout, as integreation stays at API layer, to join the cluster, running infrastructures are guanrateed to have no instability issue, when they don't need any change. When users sign in from central Uniview over Horizon or Skyline, their prior access to projects will be fully preserved with simple configuration.
One console, one credential, one‑time sign‑in
A unified operational plane gives operators a single pane of glass for visibility and action while preserving cluster autonomy. With one‑time authentication and a global console, teams can pivot between regions, run diagnostics, and execute recovery workflows without reauthenticating or relying on shared control‑plane services. This reduces cognitive load, speeds incident response, and enables consistent policy enforcement, yet keeps failure domains isolated because each cluster remains sovereign and does not depend on any shared backend.
Very low to barely any extra engineering cost
What is worth highlighting is the engineering cost and the maintenance cost. As individual OpenStack install works as they worked as a standlone cluster was, there isn't engineering cost to come into a cluster. One beautify of such architecture is that running OpenStack doesn't need transformation to join the cluster to have best transition stability. Each sites even can run at different versions of OpenStack that Uniview will detect and fall back the right versions supported.
Globally coordinated for continuity
With Uniview backup/recovery module, it complements multi-sites architecture by workload-in-motion, i.e. one-click to replicate one or multiple instances to aother OpenStack at ease. For either geo-distributed workload, a simple 3-2-1 backup, a remote env as backup target serve the goal at no hassle. For enterprise cloud, decommissioning old clusters can be fairly facilitated, when users can easily migrate their workload from one cluster to another in the manner of near live migration.
Easy migration of workload between sites
Workloads can span sites with clear replication semantics. Service like live migration and vMotion, thanks to Uniview, becomes fairly easy with click away. Backup and recovery become predictable. And every region retains its sovereignty while Uniview delivers a unified operational lens. Further exploration of such geo-distribution can be seen in an early blog here.
Talk with us for requesting a demo, consultancy or moving to a trial.
Authored by ComputingStack · At Toronto Apr 2026